I have very large PDFs. I can’t process them directly by sending them to a vision LLM because they are too large.
How can I split those PDFs in separate pages, so that I can send them to a Vision model ?
I have very large PDFs. I can’t process them directly by sending them to a vision LLM because they are too large.
How can I split those PDFs in separate pages, so that I can send them to a Vision model ?
This is a code snippet in Code Repository that takes a mediaset of PDF as input and outputs:
import json
from io import BytesIO
import pdf2image
import pypdf
from pyspark.sql import functions as F
from pyspark.sql import types as T
from transforms.api import Input, Output, transform
from transforms.mediasets import MediaSetInput, MediaSetOutput
def get_pdf_page_bytes(pdf_reader, page_number):
pdf_writer = pypdf.PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_number])
page_bytes = BytesIO()
pdf_writer.write(page_bytes)
page_bytes.seek(0)
return page_bytes
def get_bytes_from_converted_image(pdf_page_bytes, image_format="jpeg"):
pdf_page_bytes.seek(0)
image = pdf2image.convert_from_bytes(pdf_page_bytes.read())[0]
pdf_page_bytes.seek(0)
page_bytes_converted = BytesIO()
image.save(page_bytes_converted, format=image_format, resolution=100.0)
page_bytes_converted.seek(0)
return page_bytes_converted
@transform(
YOURTYPEOFDOCs_subset=MediaSetInput("ri.mio.main.media-set.xxxxxx-xxxx-xxxx-xxxxxxxxxxxx",),
# All the outputs as mediasets
YOURTYPEOFDOCs_pdf_pages=MediaSetOutput("ri.mio.main.media-set.xxxxxx-xxxx-xxxx-xxxxxxxxxxxx",
media_set_schema={"schema_type": "document", "primary_format": "pdf"},
additional_allowed_input_formats=[],
storage_configuration={"type": "native"},
retention_policy="forever",
write_mode="transactional"),
YOURTYPEOFDOCs_pictures_pages=MediaSetOutput("ri.mio.main.media-set.xxxxxx-xxxx-xxxx-xxxxxxxxxxxx",
media_set_schema={"schema_type": "imagery", "primary_format": "jpg"},
additional_allowed_input_formats=["png"],
storage_configuration={"type": "native"},
retention_policy="forever",
write_mode="transactional"),
YOURTYPEOFDOCs_pictures_as_pdf_pages=MediaSetOutput(
"ri.mio.main.media-set.xxxxxx-xxxx-xxxx-xxxxxxxxxxxx",
media_set_schema={"schema_type": "document", "primary_format": "pdf"},
additional_allowed_input_formats=[],
storage_configuration={"type": "native"},
retention_policy="forever",
write_mode="transactional"
),
YOURTYPEOFDOCs_output=Output("ri.foundry.main.dataset.xxxxxx-xxxx-xxxx-xxxxxxxxxxxx"),
)
def translate_images(
ctx,
YOURTYPEOFDOCs_subset,
YOURTYPEOFDOCs_pdf_pages,
YOURTYPEOFDOCs_pictures_pages,
YOURTYPEOFDOCs_pictures_as_pdf_pages,
YOURTYPEOFDOCs_output,
):
input_pdfs = YOURTYPEOFDOCs_subset.list_media_items_by_path_with_media_reference(ctx)
def process_pdfs(row):
# Get the media from the mediaset
media_item = YOURTYPEOFDOCs_subset.get_media_item_by_path(row["path"])
# Read the PDF
pdf_bytes = media_item.read()
pdf_reader = pypdf.PdfReader(BytesIO(pdf_bytes))
# For each page ...
result_array = []
for page_number in range(len(pdf_reader.pages)):
# Store this page as a standalone PDF
file_base_name = row["path"].replace(".pdf", "") + "_" + "page_" + str(page_number).zfill(5)
pdf_page_bytes = get_pdf_page_bytes(pdf_reader, page_number)
pdf_rid_response = YOURTYPEOFDOCs_pdf_pages.put_media_item(pdf_page_bytes, file_base_name + ".pdf")
pdf_rid = pdf_rid_response.media_item_rid
# Store this page as a picture
jpg_page_bytes = get_bytes_from_converted_image(pdf_page_bytes, "jpeg")
jpg_rid_response = YOURTYPEOFDOCs_pictures_pages.put_media_item(jpg_page_bytes, file_base_name + ".jpeg")
jpg_rid = jpg_rid_response.media_item_rid
# Convert the picture of the page to bytes, and store it again as PDF
pdf_from_jpg_bytes = get_bytes_from_converted_image(pdf_page_bytes, "pdf")
pdf_from_jpg_rid_response = YOURTYPEOFDOCs_pictures_as_pdf_pages.put_media_item(
pdf_from_jpg_bytes, file_base_name + ".pdf"
)
pdf_from_jpg_rid = pdf_from_jpg_rid_response.media_item_rid
# Create one row for this page
result_array.append([
row["mediaReference"],
row["mediaItemRid"],
page_number + 1,
file_base_name + ".pdf",
pdf_rid,
file_base_name + ".jpeg",
jpg_rid,
file_base_name + ".pdf",
pdf_from_jpg_rid,
])
pdf_page_bytes.close()
jpg_page_bytes.close()
pdf_from_jpg_bytes.close()
return result_array
schema = T.StructType([
T.StructField("source_media_reference", T.StringType(), True),
T.StructField("source_media_rid", T.StringType(), True),
T.StructField("page_number", T.IntegerType(), True),
T.StructField("pdf_page_path", T.StringType(), True),
T.StructField("pdf_page_rid", T.StringType(), True),
T.StructField("jpg_page_path", T.StringType(), True),
T.StructField("jpg_page_rid", T.StringType(), True),
T.StructField("pdf_from_jpg_page_path", T.StringType(), True),
T.StructField("pdf_from_jpg_rid", T.StringType(), True),
])
# ...
pdf_media_set_template = YOURTYPEOFDOCs_pdf_pages.media_reference_template()
jpg_media_set_template = YOURTYPEOFDOCs_pictures_pages.media_reference_template()
pdf_from_jpg_media_set_template = YOURTYPEOFDOCs_pictures_as_pdf_pages.media_reference_template()
# Apply the hit_model function in parallel using map
pdfs_rdd = input_pdfs.rdd.flatMap(process_pdfs)
pdfs_dataframe = ctx.spark_session.createDataFrame(pdfs_rdd, schema=schema)
pdfs_dataframe = (
pdfs_dataframe.withColumn("pdf_page_media_reference", F.format_string(pdf_media_set_template, "pdf_page_rid"))
.withColumn("jpg_page_media_reference", F.format_string(jpg_media_set_template, "jpg_page_rid"))
.withColumn(
"pdf_from_jpg_page_media_reference", F.format_string(pdf_from_jpg_media_set_template, "pdf_from_jpg_rid")
)
)
column_typeclasses = {
"source_media_reference": [{"kind": "reference", "name": "media_reference"}],
"pdf_page_media_reference": [{"kind": "reference", "name": "media_reference"}],
"jpg_page_media_reference": [{"kind": "reference", "name": "media_reference"}],
"pdf_from_jpg_page_media_reference": [{"kind": "reference", "name": "media_reference"}],
}
# Write the DataFrame to the specified output
YOURTYPEOFDOCs_output.write_dataframe(pdfs_dataframe, column_typeclasses=column_typeclasses)
Hi Vincent,
You’ll be happy to hear that we’re also working on this as a feature to make it easy to do in pipeline builder! It will be coming in the next couple of months.
This topic was automatically closed 14 days after the last reply. New replies are no longer allowed.
Here is an example of end-to-end pipeline that achieves this.
Specifically:
Pipeline, high level:
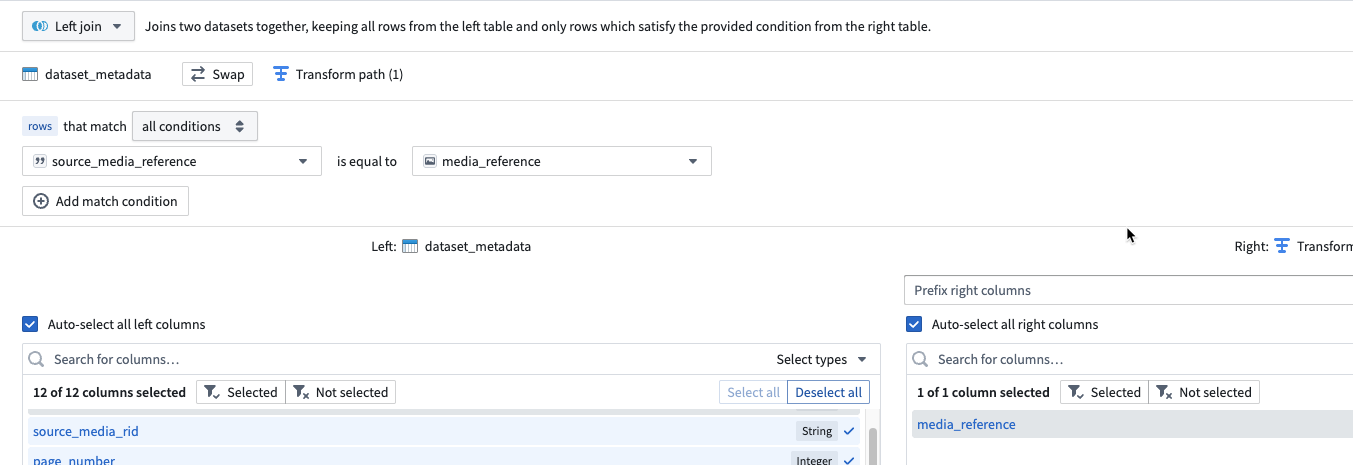
The join is only so that the mediaset is an input of the transform, so it doesn’t do anything that helps us downstream.
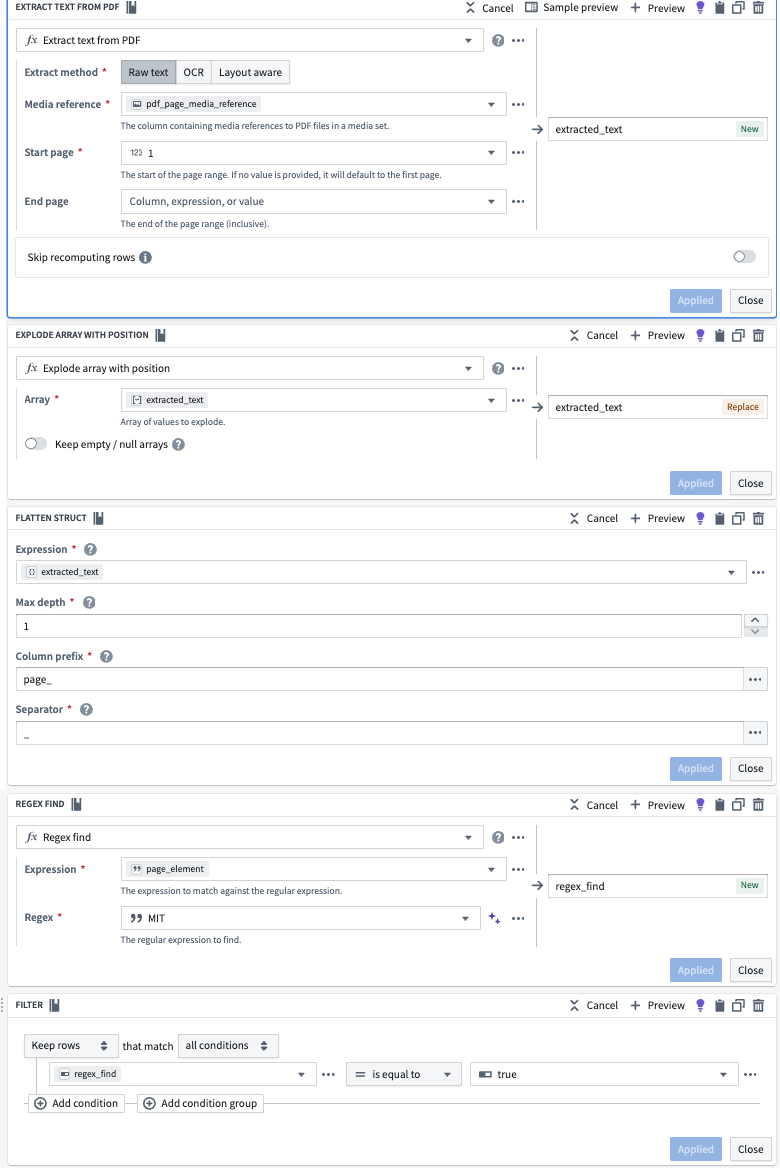
Here is the core of the processing in pipeline builder boards:
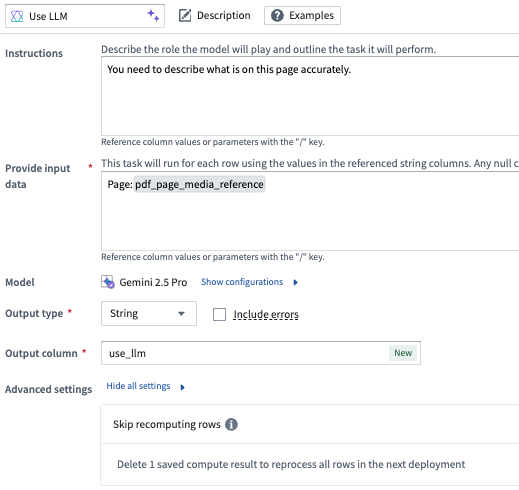
We can then apply our LLM logic:
The whole workflow should be soon doable in Pipeline Builder, as soon as extracting all the pages of a PDF as its own PDF page will be a transform supported in pipeline builder.
Also, the “join” is only required for now.