This post makes some references to https://community.palantir.com/t/how-to-do-pdf-annotation-in-workshop/3289/2
How to compute annotations in a pipeline and display them in Workshop (potentially for edition)
There are many ways to compute “chunks” from PDFs:
- should those be pages ?
- Rectangles of “interest” on pages ?
- Text itself ?
For pictures, this would only be rectangles of “interest” on the images.
Data Sourcing - Documents upload
There are multiple solutions to source documents:
- Documents can directly be uploaded to a mediaset. See https://www.palantir.com/docs/foundry/data-integration/media-sets
- Documents can be sourced from a source system like Sharepoint and written to a mediaset. See https://www.palantir.com/docs/foundry/available-connectors/sharepoint-online
- A user can as well upload new documents directly from an application like Workshop, by using Action to upload new documents. See https://community.palantir.com/t/how-to-use-an-action-to-upload-images-to-an-object/2864
Here, we will take the easiest example by manually uploading documents in a mediaset
- Go in a folder or project of your choice
- Create a mediaset
- Configure the mediaset: Transactional, PDF document type.
- Drag and drop your PDF files in the mediaset UI
Pipeline - Processing
We will want to process those documents, to extract some element of interest.
We need to:
- extract the information we need e.g. some particular information, like a date or a name; or a particular thing on a picture
- keep a reference to the original content of the document so that we can show the reference to the end user e.g. the sentence it came from, the paragraph, the page, a rectangle around the “section” of the document, etc.
The processing can be divided in multiple stages: preprocessing, text extraction, chunking, entity or information extraction and post-processing. This can happen at multiple granularity: at a whole document level, per page, or per “element” (e.g. extracted by a layout model).
There is a whole diversity of strategies and options to perform this processing. See below picture to have a high level view of it.
Zoomed-in:
Here we will take a simple example where we have PDF from which we want to extract specific pieces of information statically (e.g. date of the document, who signed the document, presence or absence of an element, etc.) and have a reference of where this is in the document.
We will see two options:
- Option A - the PDFs are digital documents, with a text layer readily available
- Option B - the PDFs are scanned documents, where OCR-ing is required
Solution A - Digital Documents PDFs - Text based
If the documents are produced digitally, the text can be extract “exactly” (aka, not via OCR). This allows for an exact match during searches in the document. This is the simplest setup.
Note: this approach might still work even on scanned documents PDFs, as you can still rely on the page number to locate the source of the extracted information. The user will have to locate the extract within the defined page which is sometimes good enough for some workflows.
The annotation are based on text extracts of the document.
Let’s setup the processing:
- Create a Pipeline Builder and import the mediaset as input
- Extract media references as the first step of the pipeline
- Output as a dataset to eventually back a “Document” Object Type. The mediaReference column will serve as a pointer from the Object instance to the document it relates to.
- Add a transform to extract the text of the PDF. The output will be an array, where each cell contains the text of one page. Also add a transform to explode the array into rows, each one representing one page. The page number will be extracted from the index from the array.
- Add a semantic chunking step - the goal here is to ask an LLM to split each page into N chunks that are semantically consistent. We do so by using the below prompt.
Note: Try multiple models !
Split the text in semantically coherent sections, these sections semantically have a start and end, and speak about one topic.
These chunks MUST contain all of the text from the topic and can span multiple lines. Section headers are useful references for chunking.
When the topic changes, the chunk changes as well.
A corresponding question/answer pair should be included in the same chunk.
Different Question/answers pairs should be chunked in different chunks, as its semantically different.
Create these "chunks" by adding "<CHUNK_BREAK>" (no spaces) into the text as a chunk delimiter. Do not change anything else in the provided text. Do not remove the <page_number> delimiter.
If you see a new line in text, keep the \n character. Do not change a single character of the provided text.
-
We now split each pages into its different chunks, by splitting on the character we introduced, exploding the array and extracting both the content and the position of each chunk within the page. We as well filter out empty chunks as those would not be useful.
-
We can now process each chunk, for example to extract entities or information that is relevant for our use-case to generate annotations we can display.
Note: We can do much more with those chunks, like validating the LLM didn’t alter the text, generate titles, extract information and aggregate back at document level, first validate which chunks contain this information, etc.
Note: Those chunks are very useful and can be used for other workflows, like RAG pipelines, by creating embedding vectors etc. which can easily be done in Pipeline Builder but out of scope for this tutorial.
You are a tool for <industry> which extract information from <type of documents>
You are looking for <type of information>, these are <description>
Your goal is to parse the following page text into an array of JSON structs where every entry contains the following fields:
- <key>: <description of what to extract, format, type>
- <key>: <description of what to extract, format, type>
- <key>: <description of what to extract, format, type>
If the text doesn't contain an a <type of information> return null
The output should be a valid JSON (without \n or or other escaping)
- We will need to post-process the output, to extract it in a easily readable format. We filter out chunks that did not have this information, we explode the found information (e.g. if one chunk contains a table, you might have multiple hits, hence the array), you parse out the json keys and flatten it in columns, and we finally generate a primary key.
At this stage, we obtained
- a dataset containing “the document references”
- a dataset containing chunks (aka “pieces of the document”), with the page they belong to, their content, and with a reference to the document they belong to
- a dataset containing elements we wanted to extract, with a reference to the chunk it was extracted from
Solution B - Scanned Documents PDFs
If the document are not digital (aka, no text layer exists in the PDF), it is possible to use OCR or Layout models to extract the information.
Note: for documents containing parts that should be processed differently (e.g. charts, schematics, tables, …), it is possible to use a mix of Vision models and Layout extracted to extract granularly each piece of information (e.g. all data points of a chart, etc.). This won’t be covered here as it is more advanced but it is possible.
B1 - Page level
The first option is to do the same as for Solution A, but to use the “OCR” option in step 4. The processing will be the same, but you won’t be able to highlight the exact text segment once in Workshop, but only jump to the page from which it was extracted (and this is often enough !).
B2 - Rectangle extraction via Layout model or other model
The second option is to use a Layout Model. As this model is experimental, it might not be available or enabled on your Foundry enrollment.
If available you will see the “Document Information Extraction” model in Model Catalog (navigate to workspace/model-catalog).
If you don’t see it, you might want to reach out to the administrator of your Foundry enrollment, who might be able to enable this model in Control Panel.
The chunks will have exact coordinates of “rectangles” on the page. where the structure of the page is used to extract blocks of information.
As of today, you can call it from Code Repository but this might be soon available in Pipeline Builder.
Let’s do the layout extraction in Code repository (see this other post):
https://community.palantir.com/t/how-to-use-a-layout-model-on-pdfs/3290/2
With this approach you will have
- a dataset containing “the document references”
- a dataset containing chunks (aka “pieces of the document”), with the page they belong to, their content, and with a reference to the document they belong to, and the exact coordinates (rectangle) of the “chunk”
You might want to create a dataset containing elements we wanted to extract, with a reference to the chunk it was extracted from, but this step is similar Solution A - steps 7 and 8 in particular.
Ontology - Ontology setup
At this stage, we have a few datasets produced by our pipeline (via code repository or pipeline builder):
- a dataset containing “the document references” which will back the “Document” Object Type
- a dataset containing chunks, with their page, content, and potentially coordinates which will back the “Chunks” Object Type
- [optional] a dataset of “elements” (e.g. entities or relevant information) extracted) which will back the “Piece of information” object. You can make the name more specific to your use-case (e.g. like a contract clause)
Objects types will be linked together like on the below picture.
You can create the Object Types like from any dataset, by clicking the top right “Actions > Create Object Type”
You can use the MediaItemRid (not stable between pipelines snapshot) or the “path” (stable between pipelines snapshots) of the document as a primary key.
You can then create links between the Object Types, using the foreign/primary keys:
Make sure that the media reference property is of type “Media reference” in Ontology manager
You will need to specify the mediaset where those files are stored.
Application - Workshop with PDF Viewer Widget
We now have an Ontology of 3 Object Types. We can create our application to show the document, the chunks and the pieces of information we want.
Let’s build our application
- Create a Workshop application (from your folder, right click, New > Workshop)
- Add an Object list or table displaying all Documents Objects instances, to be able to select one, which will be stored in the “Active object” variable
- Add the “PDF Viewer” widget
See Documentation for the PDF Viewer in Workshop - https://www.palantir.com/docs/foundry/workshop/widgets-pdf-viewer/
- Configure the PDF viewer widget. Pass the “active document” as an input and select the property of the object which stores the media reference, which will be displayed in the Viewer.
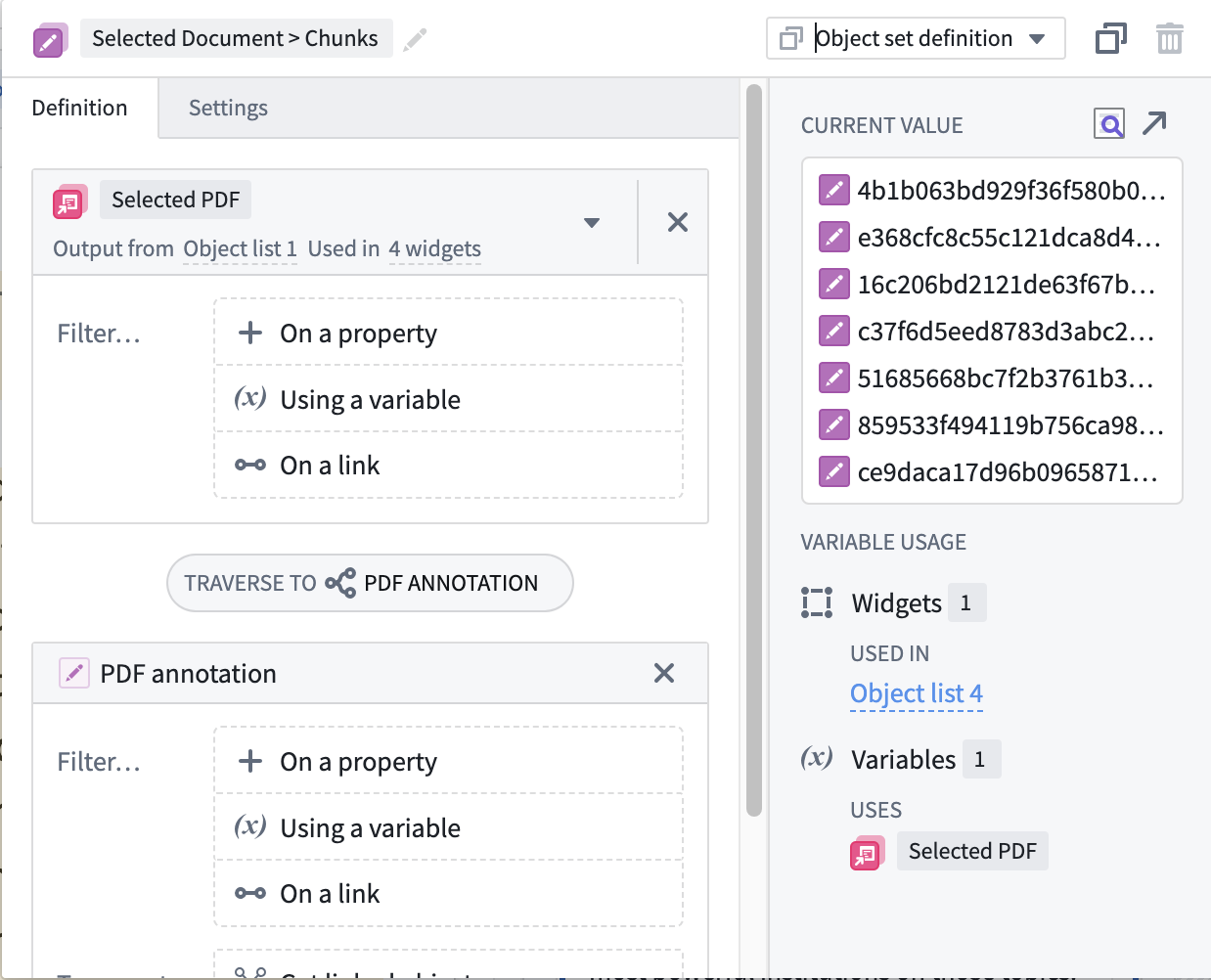
- Given you established links in the Ontology, you can pivot from the currently selected document to the chunks belonging to the document. Create a variable to “traverse to” the Chunks.
- You can show a list of your chunks to the user, so that you get one chunk selected in a variable “Selected Chunk”
Display the chunk on the document will depends on the information stored in your chunk, and so on your choices you made earlier in the tutorial.
If you have only the “page number” in your chunks
- Create a variable to extract the page of the selected chunk
- Use this variable to back the “active page number” of the PDF Viewer widget
On click on a chunk in the list of chunks, the PDF will be scrolled to the relevant page !
If you have only text in your chunks
Very similar to the page scroll, you can pass some text to highlight in the document.
- Create a variable to extract the content detected in the chunk and pass it to the PDF Viewer widget to “highlight” this text.
On click on a chunk in the list of chunks, the PDF will be scrolled to the page containing this text !
Note: This is an actual “search” of text in the document. Some PDFs have special characters (bullets lists, etc.) which are not extracted during the Pipeline processing, and hence cannot be matched back on their original PDF as the actual text in the chunk and text in the PDF will not exactly match. In this case, you might need to pivot to the other approaches (page or chunk).
If you have the coordinates of the box of the chunk
We will this time configure the PDF Viewer widget by passing the variable containing all the chunks, to the widget, and specifying which property of the Object Type contains the bounding box.
Alternative: You can also display only the selected bounding box of your choice by passing a “select” variable containing the chunks you want to display (e.g. active or multi-selected chunks).
Note: You will also obtain a variable containing the “currently selected bounding box”, see arrow in purple on the below picture.
Note: You can use this “selected annotation” variable both way - to get the selection of the user in the PDF Viewer, but as well to select a particular bounding box. Hence you can pass all the chunks to the PDF Viewers, and highlight the one that is currently actively selected in the object list.
On click on a chunk in the list of chunks, the exact bounding box be drawn on the PDF !
Note: If you want as well the PDF to scroll to the right page, refer to the previous “If you have only the “page number” in your chunks“ section: you need to pass the page number in the ”active page“ configuration of the PDF Viewer widget.