I’m building an app which allows users to upload an image of their meal and receive a summary of the nutrition facts in their meal. Right now, I am using the media uploader widget in Workshop which sends images to a media set. Since there isn’t a way to make the pipeline incremental with a mediaset as the source dataset, I tried doing the following:
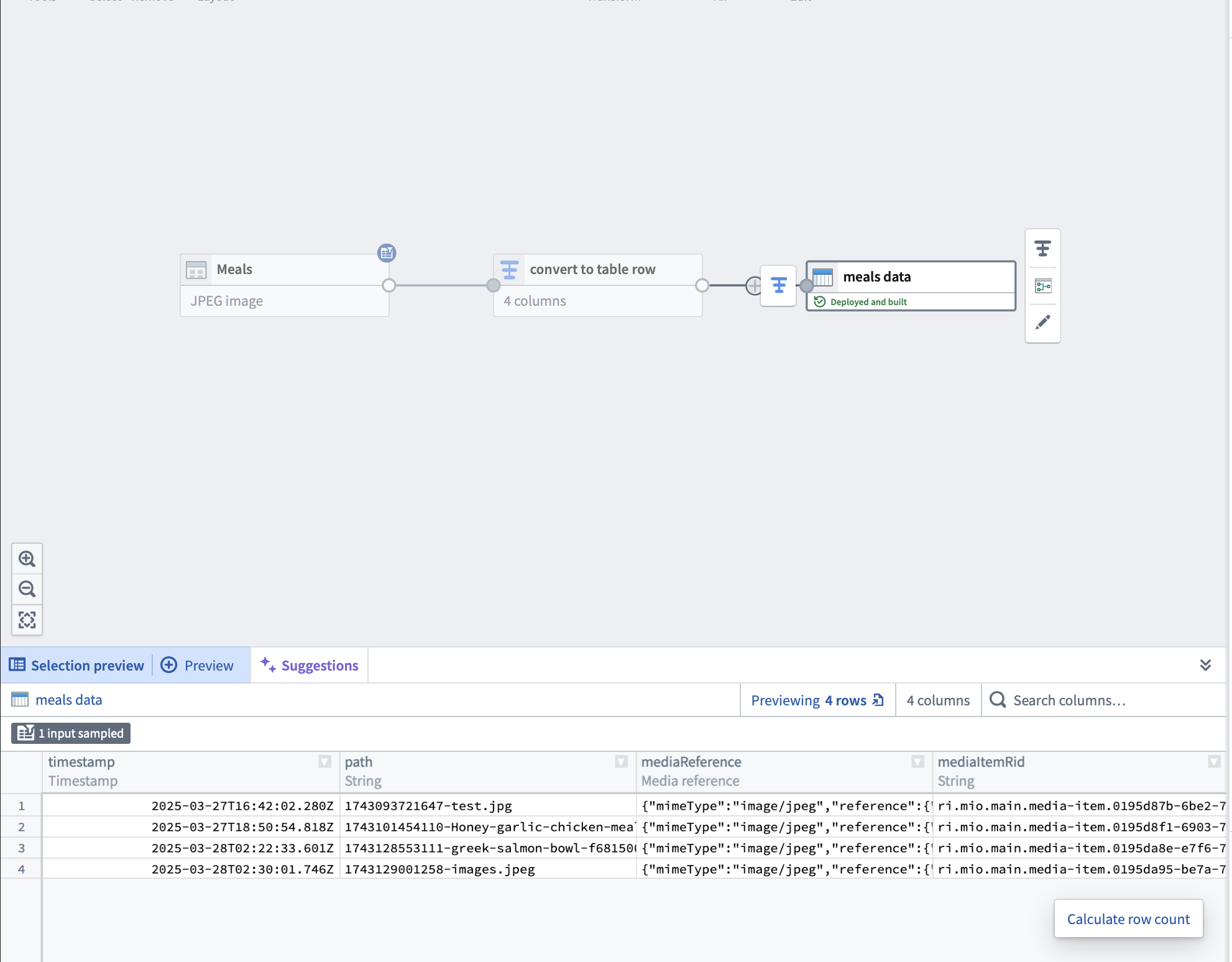
In one pipeline, convert the mediaset to tablerows, then output a dataset called “meals data”
In another pipeline, import “meals data” and then try to run transforms / LLM functions on that data, and ultimately create a new object of that type. I want this process to be automated such that whenever a new user uploads an image, it runs through the pipeline and creates that new object.
When I tried doing this, I get an error saying “Failed to load preview” when I try to run LLM on the “meals data” dataset. Is there a different way to accomplish this functionality?
To confirm, is the idea here that the first pipeline is using the “append only new rows” write mode so that the second pipeline can be incremental?
You’re probably hitting the same error as https://community.palantir.com/t/permissions-error-when-using-pipeline-builder-to-convert-media-set-into-dataframes/796/9. I believe that you should be able to resolve this by adding the original media set as another input (with the SNAPSHOT read mode, since it’s a media set) to the second pipeline. In the second pipeline, you’d also convert the media set to table rows and then inner join it with the append-only input. You don’t need to actually include any columns from the media set input as part of the join - the only reason for the join is to make sure that the media set is indeed treated as an input, allowing the job token to read the media items.
My issue is basically the second issue that you describe in the linked post. I have one pipeline that has a media set which gets converted and outputted as a dataset. Then, I have another pipeline that takes that outputted media set and tries to process it. For clarity, I’ve included screenshots.
Sorry for the delayed response. I’m not sure if I’m understanding your proposed solution correctly. Are you saying that in my second pipeline (second screenshot), I should add the original media set as a separate input, convert it to table rows, then inner join that with the “meals data” dataset (which is the output from the first pipeline)? Then, would I use the resulting table (from the inner join) and pipe that into the LLM prompt? In your other post, you mentioned that media references can only be accessed where the media itself is an input, so my understanding is that this inner join accomplishes that and allows me to pass in the media references into the LLM.
Would I still make the build schedule based on the “meals data” dataset? When a new entry gets appended to that dataset, it doesn’t automatically update the inner joined table, right? I’m trying to wrap my head around how the general flow (from original image to object) works in this solution. If you wouldn’t mind, could you explain your proposed solution again and reference the definitions that I have in my screenshots? Apologies for the confusion.
The inner joined table isn’t a dataset - it’s just part of the “recipe” for building Meal Object Dataset, so you don’t need to worry about updating it individually. As part of building Meal Object Dataset, the inner join will automatically happen, and you don’t need to think about this aspect when you define your build schedules.
I do suggest making a single schedule, with the media set being updated the “trigger condition,” Meal Object Dataset being the “target resource,” and the “include upstream resources” option enabled.
For further clarity, here’s a screenshot of a pipeline (the “second” pipeline) with the same structure:
And here is my recommended schedule configuration for that pipeline. This will automatically build the appended_media_references dataset, followed by the incrementally_processed_output_dataset dataset, because the Foundry Build infrastructure automatically executes jobs in the appropriate dependency order as part of a build.
Thank you so much for explaining this and including clarifying screenshots. This whole time I thought that I had to create the build schedule in pipeline builder itself, but the only options for When to build were “When a specific dataset updates,” or “At a specific time.” I didn’t realize that if I created the schedule in Data Lineage, I would be able to build when a specific resource (in this case the media set) updates.
This got me thinking: If I am able to create my build schedule around the media set being updated, do I even need an intermediary “meals data” dataset to begin with? Originally, I introduced this intermediary dataset because I needed a way of satisfying the “When a specific dataset updates” requirement in the pipeline builder build schedule. Is the reason to still maintain this intermediary dataset to reduce unnecessary computation by allowing the pipeline to be incremental, making it so that only new rows are appended? Please correct me if I’m understanding this incorrectly.
Again, thank you very much for your detailed assistance with this, I greatly appreciate it!
Yup, that would be the only reason to maintain the intermediary dataset in this case. But if the only expensive operation in your pipeline is the Use LLM board, you can just use the Skip computing already processed rows option to essentially achieve the same effect. The incremental-with-intermediary-dataset implementation may still be strictly speaking more efficient, but it would be a quite marginal difference that would probably not justify the increased complexity.
Incidentally, you can in fact select a media set when using the “when specific datasets update” option in Pipeline Builder, as below. I’ll see if we can change this language to “resource” to be less confusing!