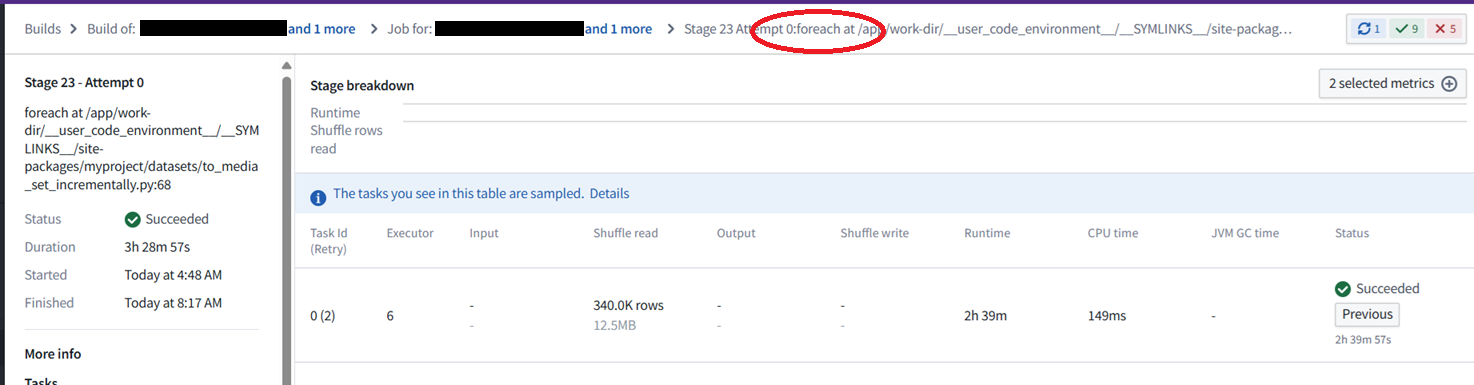
I have a working PySpark file that writes a subset of files from a dataset to a transactional media set. It uses the second example from the docs here; however, the for loop is running on a single executor, and at this rate it would take 1-2 months to convert all the PDFs.
In the code below, I try to omit the for loop by using put_dataset_files() instead, but I get an error that “A DataFrame object does not have an attribute filesystem”.
Is it possible to either (1) convert input.filesystem().files() back to an input format (or other format compatible with put_dataset_files) or (2) replace a for loop with something that runs in parallel?
fs = pdfs_input.filesystem()
df = fs.files() # Get files as a dataframe of metadata
df = df.limit(10)
# **df= df.toInputOrToOutputOrToSomeOtherMagicHere**
# Output PDFs to a media set
media_set_output.put_dataset_files(
df, # ERROR HERE: A "DataFrame" object does not have an attribute "filesystem"
ignore_items_not_matching_schema=True,
ignore_items_failing_to_convert=True
)
Hi @sandpiper, I tried your suggestion, and I think it still ran the foreach on one executor. Please see below. Is there any information I can give you that would help troubleshoot this issue?
# Modified from CodeStrap's post at https://community.palantir.com/t/pipeline-builder-incremental-mediasets-pdf-extraction/1279/5
from transforms.api import transform, Input, Output, incremental, configure
from transforms.mediasets import MediaSetOutput
from pyspark.sql import functions as F
import os
import logging
from conjure_python_client._http.requests_client import ConjureHTTPError
from urllib3.exceptions import UnrewindableBodyError
logger = logging.getLogger(__name__)
@configure(profile=[
"EXECUTOR_MEMORY_MEDIUM",
"DYNAMIC_ALLOCATION_ENABLED",
"DYNAMIC_ALLOCATION_MIN_16",
"DRIVER_MEMORY_OVERHEAD_LARGE",
"EXECUTOR_MEMORY_OVERHEAD_MEDIUM",
"EXECUTOR_CORES_SMALL",
"DRIVER_MEMORY_MEDIUM",
"DRIVER_CORES_MEDIUM"])
@incremental(snapshot_inputs=["pdfs_input"], v2_semantics=True)
@transform(
metadata_output=Output("ri.foundry.main.dataset.aa1e8a25-3252-4e48-8b88-db441bd065bc"),
media_set_output=MediaSetOutput("ri.mio.main.media-set.e8d1c25d-1d94-468e-981d-62f53aa19f17"),
pdfs_input=Input("ri.foundry.main.dataset.052024ea-9eb0-44b5-9033-afbc7bc1a99d")
)
def compute(ctx, pdfs_input, metadata_output, media_set_output, limit_rows=True, limit=10000):
fs = pdfs_input.filesystem()
df = fs.files() # Get files as a dataframe of metadata
df = df.withColumn(
'modified',
F.from_unixtime(F.col('modified') / 1000).cast("timestamp")
) # Convert last modified time (UTC) from long to timestamp
df = df.withColumn('processed_at', F.current_timestamp()) # Add a timestamp
if hasattr(ctx, '_is_incremental'):
df = df.withColumn('is_incremental', F.lit(ctx.is_incremental)) # Check if build is running incrementally
if ctx.is_incremental:
output_df_previous_dataframe = metadata_output.dataframe('previous')
df = df.join(output_df_previous_dataframe, how="left_anti", on="path")
if df.count() == 0:
ctx.abort_job() # This stops the build schedule's infinite loop after processing all input pdfs
else:
df = df.withColumn('is_incremental', F.lit(False))
# Conditional row limiting based on the parameter
if limit_rows:
df = df.orderBy(F.col("modified").desc(), F.col("path").desc()).limit(limit)
metadata_output.write_dataframe(df) # Write output dataset
# Define media set converter function
def convert_file(current_file):
try:
with fs.open(current_file.path, 'rb') as f:
filename = os.path.basename(current_file.path)
media_set_output.put_media_item(f, filename)
except ConjureHTTPError:
logger.warning("ConjureHTTPError: " + current_file.path)
except UnrewindableBodyError:
logger.warning("UnrewindableBodyError: " + current_file.path)
# Convert to media set
df.foreach(convert_file)
@Joel
when you do put_dataset_files, you should directly pass in the dataset input instead of df.
If your pdfs_input is a dataset of files, you can try
media_set_output.put_dataset_files(
pdfs_input,
ignore_items_not_matching_schema=True,
ignore_items_failing_to_convert=True
)
@sarahwang, my pdfs_input is too large (4M+ PDFs) and errored out when I tried put_dataset_files previously. In my full code, I use the below logic to reduce the size of the input. Is there a way to then bring the filtered df back to a format that put_dataset_files can accept? If not, would you write the filtered files to a new dataset, and then pass that to put_dataset_files?
How about try to specify the media set file size limit?
def put_dataset_files(
self,
dataset_input: TransformInput,
ignore_items_not_matching_schema: bool = False,
ignore_items_failing_to_convert: bool = False,
file_name_pattern: str = None,
file_size_limit_bytes: int = None,
):
“”"
Copies the files in the input dataset into this media set.
Additional options: ignore_items_not_matching_schema: Unless set to true, will error if the file does not match
the expected schema of the media set file_name_pattern: A UNIX-style file name pattern may be specified to filter the items from input dataset file_size_limit_bytes: Files whose size in bytes exceeds this limit will be ignored
Your dataframe may only have one partition (possibly as a consequence of the limit operation). Try this:
df.repartition(32).foreach(convert_file)
Note that one could imagine (though I don’t have concrete evidence of this, and I’m fairly sure it’s not true) that automatic coalescing to one partition also happens during the df → rdd conversion that happens as part of foreach. To be extra safe, then, you can try the following:
Thank you so much @sandpiper! df.repartition(32).foreach(convert_file) solved this issue. This reduced the foreach stage of the build from 1h 45m to 7m! This brings the total ETA from 45 days to 10-15 days due to the other stages, which I’m working on troubleshooting now. Will post updates, but also pasting latest code for reference.
# Modified from CodeStrap's post at https://community.palantir.com/t/pipeline-builder-incremental-mediasets-pdf-extraction/1279/5
from transforms.api import transform, Input, Output, incremental, configure
from transforms.mediasets import MediaSetOutput
from pyspark.sql import functions as F
import os
import logging
from conjure_python_client._http.requests_client import ConjureHTTPError
from urllib3.exceptions import UnrewindableBodyError
logger = logging.getLogger(__name__)
@configure(profile=[
"EXECUTOR_MEMORY_MEDIUM",
"DYNAMIC_ALLOCATION_ENABLED",
"DYNAMIC_ALLOCATION_MIN_16",
"DRIVER_MEMORY_OVERHEAD_LARGE",
"EXECUTOR_MEMORY_OVERHEAD_MEDIUM",
"EXECUTOR_CORES_SMALL",
"DRIVER_MEMORY_MEDIUM",
"DRIVER_CORES_MEDIUM"])
@incremental(semantic_version=2, snapshot_inputs=["pdfs_input"], v2_semantics=True)
@transform(
metadata_output=Output("..."),
media_set_output=MediaSetOutput("{**Transactional** media set}"),
pdfs_input=Input({**4M PDFs** dataset})
)
def compute(ctx, pdfs_input, metadata_output, media_set_output, limit_rows=True, limit=10000):
fs = pdfs_input.filesystem()
df = fs.files() # Get files as a dataframe of metadata
df = df.withColumn(
'modified',
F.from_unixtime(F.col('modified') / 1000).cast("timestamp")
) # Convert last modified time (UTC) from long to timestamp
df = df.withColumn('processed_at', F.current_timestamp()) # Add a timestamp
if hasattr(ctx, '_is_incremental'):
df = df.withColumn('is_incremental', F.lit(ctx.is_incremental)) # Check if build is running incrementally
if ctx.is_incremental:
output_df_previous_dataframe = metadata_output.dataframe('previous')
df = df.join(output_df_previous_dataframe, how="left_anti", on="path")
if df.count() == 0:
ctx.abort_job() # This stops the build schedule's infinite loop after processing all input pdfs
else:
df = df.withColumn('is_incremental', F.lit(False))
# Conditional row limiting based on the parameter
if limit_rows:
df = df.orderBy(F.col("modified").desc(), F.col("path").desc()).limit(limit)
metadata_output.write_dataframe(df) # Write output dataset
# Define media set converter function
def convert_file(current_file):
try:
with fs.open(current_file.path, 'rb') as f:
filename = os.path.basename(current_file.path)
media_set_output.put_media_item(f, filename)
except ConjureHTTPError:
logger.warning("ConjureHTTPError: " + current_file.path)
except UnrewindableBodyError:
logger.warning("UnrewindableBodyError: " + current_file.path)
# Convert to media set
df.repartition(64).foreach(convert_file)