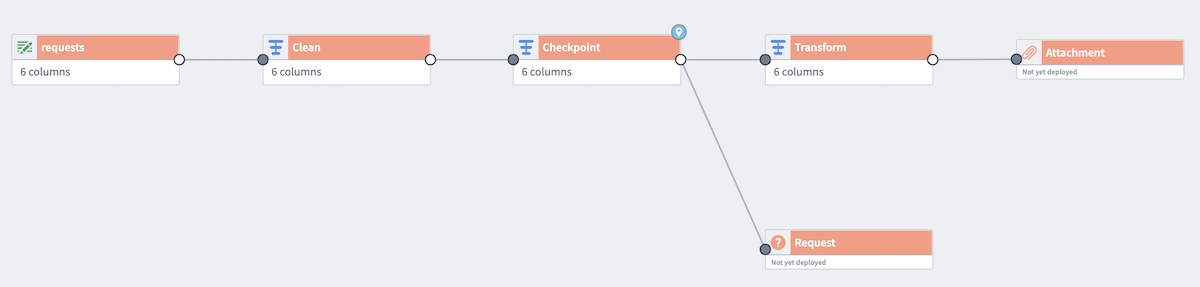
I understand the performance benefits of a checkpoint when a pipeline has multiple outputs that share logic. However, I don’t want the checkpointed data to remain if the inputs update.
More concretely: In this example from the docs, if requests was an actual input dataset, could the checkpoint cause the outputs to be built off of an inaccurate older version of requests? Or just it just avoid reprocessing within a single build?
@wgentry thanks for the question! Currently, checkpoints are not persisted beyond the time of build. So, if you have a schedule to rerun the build of your outputs, or you manually trigger a build, all input data updates will be respected (assuming you aren’t doing crazy things with your write mode).
They only exist to (1) only process the data up to the checkpointed transform once for multiple outputs in the same job group and (2) allow two outputs to share the same output of a non-deterministic transformation.