Thank you for your detailed reply.
Before consolidating the two datasources, i ran them through separate pipelines as an example to learn the process. In the “Use LLM” transform, i used GPT-4o and the following time is what it took to build all the datasets.
Datasource 1. FAA Docs: 3 hrs
Datasource 2. eCFR Title14: 8 - 10 hrs.
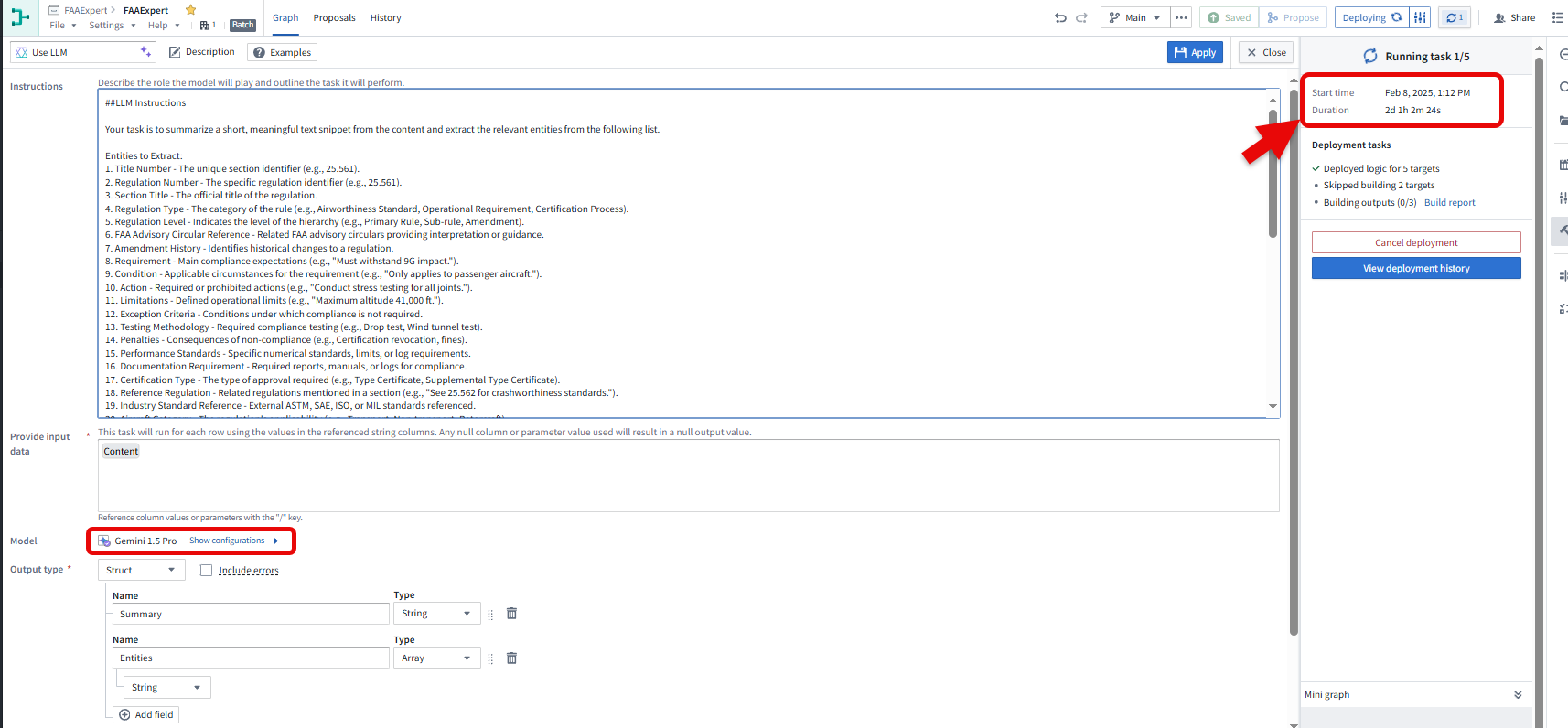
When combined the datasrouces, it took 10 - 12 hrs to build using GPT-4o. However, with Gemini 1.5 pro, it been building for more than 2 days now (Refer screenshot)
Why Gemini 1.5 pro? - After some trials, i thought that Gemini is doing a better job in extracting array of entities for each chunk.
I’ve been playing around with the entity extraction as the reply from agent is not as detailed or accurate as expected and is not able to link all the relevant details from all the datasources.
Any recommendation on how i could improve the agent’s reply and reduce build time? I understand it is a pretty broad question. I’m currently checking for any similar examples in marketplace. I have pasted the LLM instruction i used in the “Use LLM” transform.
Thank you
Kannan
Instruction used in “Use LLM” Transform:
##LLM Instructions
Your task is to summarize a short, meaningful text snippet from the content and extract the relevant entities from the following list.
Entities to Extract:
- Title Number - The unique section identifier (e.g., 25.561).
- Regulation Number - The specific regulation identifier (e.g., 25.561).
- Section Title - The official title of the regulation.
- Regulation Type - The category of the rule (e.g., Airworthiness Standard, Operational Requirement, Certification Process).
- Regulation Level - Indicates the level of the hierarchy (e.g., Primary Rule, Sub-rule, Amendment).
- FAA Advisory Circular Reference - Related FAA advisory circulars providing interpretation or guidance.
- Amendment History - Identifies historical changes to a regulation.
- Requirement - Main compliance expectations (e.g., “Must withstand 9G impact.”).
- Condition - Applicable circumstances for the requirement (e.g., “Only applies to passenger aircraft.”).
- Action - Required or prohibited actions (e.g., “Conduct stress testing for all joints.”).
- Limitations - Defined operational limits (e.g., “Maximum altitude 41,000 ft.”).
- Exception Criteria - Conditions under which compliance is not required.
- Testing Methodology - Required compliance testing (e.g., Drop test, Wind tunnel test).
- Penalties - Consequences of non-compliance (e.g., Certification revocation, fines).
- Performance Standards - Specific numerical standards, limits, or log requirements.
- Documentation Requirement - Required reports, manuals, or logs for compliance.
- Certification Type - The type of approval required (e.g., Type Certificate, Supplemental Type Certificate).
- Reference Regulation - Related regulations mentioned in a section (e.g., “See 25.562 for crashworthiness standards.”).
- Industry Standard Reference - External ASTM, SAE, ISO, or MIL standards referenced.
- Aircraft Category - The regulation’s applicability (e.g., Transport, Non-transport, Rotorcraft).
- Component Category - Component type (e.g., Wing, Landing Gear, Electrical System).
- Aircraft System - Related aircraft subsystems (e.g., Flight Controls, Avionics).
- Impact on Other Regulations - Regulatory interdependencies (e.g., “Compliance with 25.561 affects 25.601.”).
- Department - The regulatory domain responsible (e.g., Flammability, Damage Tolerance, Structural Integrity).
- Regulatory Body - The agency enforcing the regulation (e.g., FAA, EASA).
- FAA Office - The specific FAA office responsible (e.g., Transport Airplane Directorate).
- Manufacturer Responsibility - Specific obligations for OEMs (e.g., Boeing, Gulfstream).
- Operator Responsibility - Specific obligations for airlines or aircraft owners.
- Effective Date - The date when the regulation became applicable.
- Revision Date - The latest publication date of the regulation.
- Regulatory Status - Whether the rule is Active, Amended, or Revoked.
- Jurisdiction - The geographical scope (e.g., US, EU, International).
- Document Type - The type of document referencing the regulation (e.g., MOC, Rulemaking Docket).
- Interpretation Notes - Additional clarifications or official legal interpretations.
- Public Comment Period - Timeline for stakeholder feedback.
- Legislative Origin - The underlying legislative statute that led to the regulation (e.g., Federal Aviation Act).
##Entity Extraction Guidelines:
- Each extracted entity should be in singular form without any prefixes, adjectives, or explanations.
- DO NOT use generic or meaningless single-letter entities like “J”.
- DO NOT extract random, isolated numbers unless they represent meaningful identifiers (e.g., 25.561).
- DO NOT use any meaningless sequences of numbers like 1, 2, 17 unless they refer to a regulation.
- DO NOT extract a list of multiple unrelated regulations (e.g., “23, 12, 10”) as a single entity.
-Extract data like 8100.8D, 8100-9 etc
If a content snippet is linked to a Title/Chapter/Subchapter, the entity should be extracted in full format.
For example:
If a text is linked to “Title 14 / CHAPTER III - COMMERCIAL SPACE TRANSPORTATION, FEDERAL AVIATION ADMINISTRATION, DEPARTMENT OF TRANSPORTATION / PART 406 - INVESTIGATIONS”,
DO NOT extract just “Subchapter B - Procedure”. Instead, preserve the full structure.