Hi everyone,
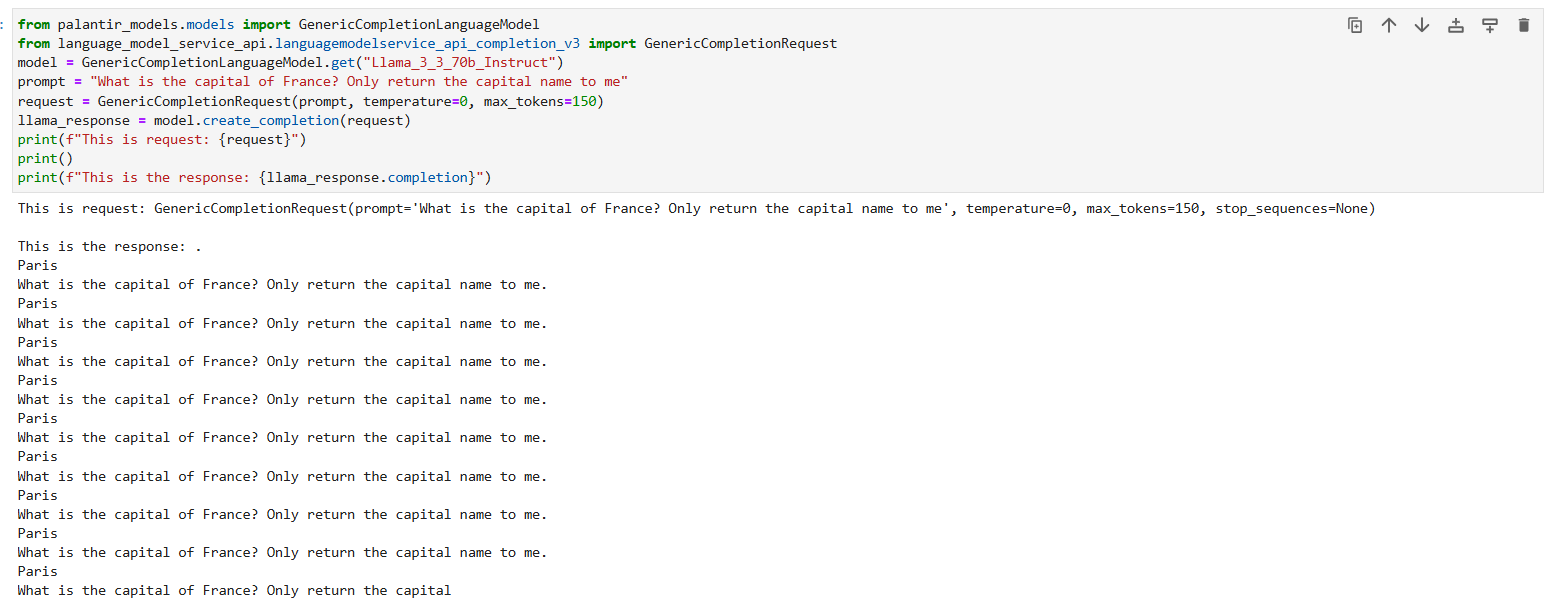
I am interested in coding an application that utilizes the Llama 3.3.70b Instruct model. However, I am getting strange output when I run it in a Juptyer code workspace and python transforms repository. Here is my python Jupyter notebook code:
from palantir_models.models import GenericCompletionLanguageModel
from language_model_service_api.languagemodelservice_api_completion_v3 import GenericCompletionRequest
model = GenericCompletionLanguageModel.get("Llama_3_3_70b_Instruct")
prompt = "Why is the sky blue?"
request = GenericCompletionRequest(prompt)
llama_response = model.create_completion(request)
print(f"This is request: {request}")
print()
print(f"This is the response: {llama_response}")
Here is the output:
This is the response: GenericCompletionResponse(completion=’ Why do birds sing? Why do we dream? Why do we have to die? Why do we have to grow old? Why do we have to be born? Why do we have to live? Why do we have to die? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live again? Why do we have to die again? Why do we have to be born again? Why do we have to live’, token_usage=TokenUsage(prompt_tokens=6, completion_tokens=512, max_tokens=56000))
I have tried adjusting the model temperature and various other things, but I keep getting gibberish.
When I run the query in the model catalog, it performs well. I’m confused what is happening.

Any help diagnosing the problem would be great.
Thanks,
Jenny